AWS ECS, EC2, and Warm Pools: advantages and gotchas

Fargate vs. EC2 Auto Scaling groups
First, we need to understand the concept of capacity providers in ECS. A capacity provider is a resource that provides the capacity to run ECS tasks. The two main types of capacity providers in ECS are Fargate and EC2 Auto Scaling groups.
Fargate is a serverless compute engine for containers that allows you to run containers without having to manage the underlying infrastructure. With Fargate, you pay only for the vCPU and memory your container uses, and you don’t have to worry about provisioning or scaling the underlying infrastructure. Fargate provides great scalability and flexibility: you virtually have an unlimited capacity to run containers right when you need them. Sounds perfect, but what’s the catch?
First of all, every advantage has its price. Fargate is more expensive than running containers on EC2 instances. If you have a large number of containers running 24/7, Fargate can be quite costly. Also, Fargate fleets receive new CPU models much later than EC2 instances. For example, AWS added support for Graviton 3 CPUs to Fargate only after they introduced Graviton 4 CPUs to EC2 instances. Considering that every new generation of Graviton CPUs brings significant performance improvements, this can be a considerable disadvantage for CPU-intensive workloads.
Another way to provide capacity for ECS tasks is by using EC2 instances. Technically, any EC2 instance or even an external server can be used by ECS as a container instance as soon as it runs an ECS agent and registers itself with the ECS cluster. However, the most common and handy way to use EC2 instances with ECS is by creating an EC2 Auto Scaling group. An Auto Scaling group is a group of EC2 instances that automatically scales in and out based on your needs. If you register an EC2 Auto Scaling group as a capacity provider in ECS, ECS will automatically launch and terminate EC2 instances to fit the desired number of tasks. This way, you don’t have to worry about managing the underlying infrastructure and can focus on running your containers.
This approach’s advantages mirror the disadvantages of Fargate. Running containers on EC2 instances is cheaper than using Fargate, and you can upgrade to the latest CPU models right when they are released. Also, you can use burstable (T-type) instances with ECS, which can be a cost-effective solution for workloads with variable CPU usage.
One of the disadvantages is a more complex setup: EC2 Auto Scaling group has to be properly configured and registered as a capacity provider in ECS. However, this is a one-time setup, and you can forget about it once you have it done.
The other disadvantage is slower scaling. When you need more capacity, ECS has to launch new EC2 instances, which may take time. However, this can be partially mitigated by using warm pools.
Fantastic warm pools and where to find them
Warm pool is a feature of EC2 Auto Scaling groups that allows you to keep a pool of pre-initialized EC2 instances. Those instances are kept in a stopped, hybernated, or even running state, depending on the Auto Scaling group configuration. When the Auto Scaling group needs to launch new instances, it can use the instances from the warm pool instead of launching new ones. This can significantly reduce the time needed to scale out and improve the availability of your ECS tasks.
EC2 instances in a stopped state cost almost nothing. You pay only for the EBS volumes attached to the instances. This makes warm pools a cost-effective solution for workloads with variable loads.
In this article, we won’t cover the creation of an EC2 Auto Scaling group for ECS and registering it as a capacity provider. There are plenty of tutorials on this topic on the Internet. Instead, we will focus on configuring warm pools and the gotchas you may encounter.
Configuring warm pools
We recommend reading this article to the end before configuring warm pools. This way, you will be aware of the gotchas and can avoid them.
Creating a warm pool is pretty straightforward. On the Auto Scaling group page, switch to the Instance management tab, scroll down a bit, and click Create warm pool.
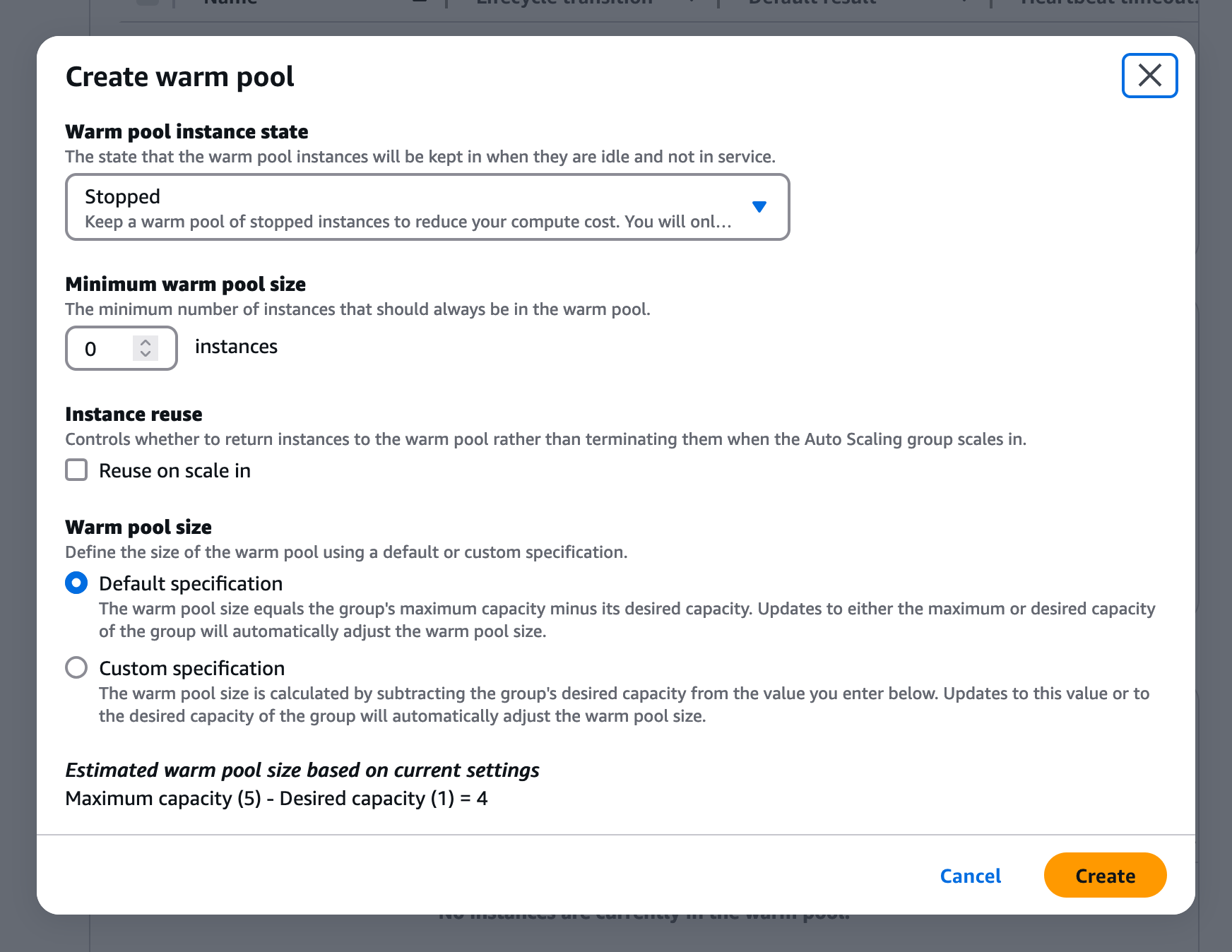
The default settings are usually fine, but you can adjust them to fit your needs.
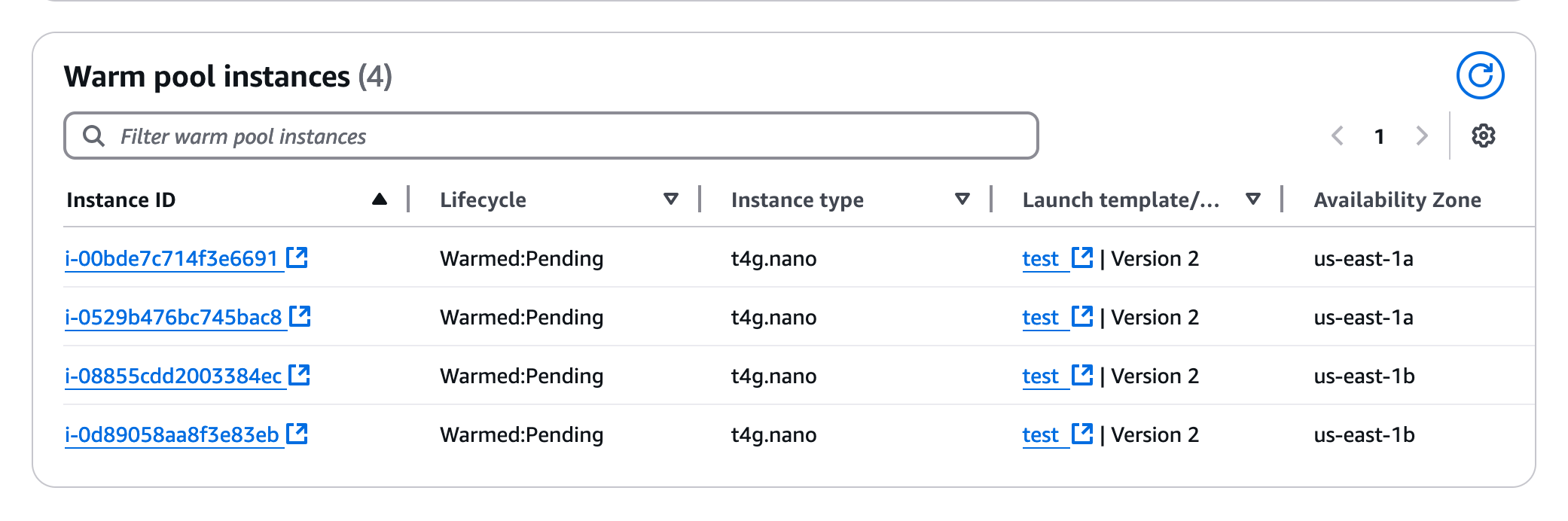
After you click Create, you’ll see the warm pool being filled with instances. You can see the status of the instances at the very bottom of the Instance management tab:
If you want to add a warm pool to your CloudFormation template, you can use the following snippet (where EC2AutoScalingGroup is your Auto Scaling group resource in the template):
EC2AutoScalingGroupWarmPool:
Type: AWS::AutoScaling::WarmPool
Properties:
AutoScalingGroupName: !Ref 'EC2AutoScalingGroup'
InstanceReusePolicy:
ReuseOnScaleIn: falseWait, that was too easy! What are the gotchas? Let’s discuss them.
Gotcha #1: Premature registration in ECS
After you created a warm pool, you may notice the following warning on your ECS cluster page:
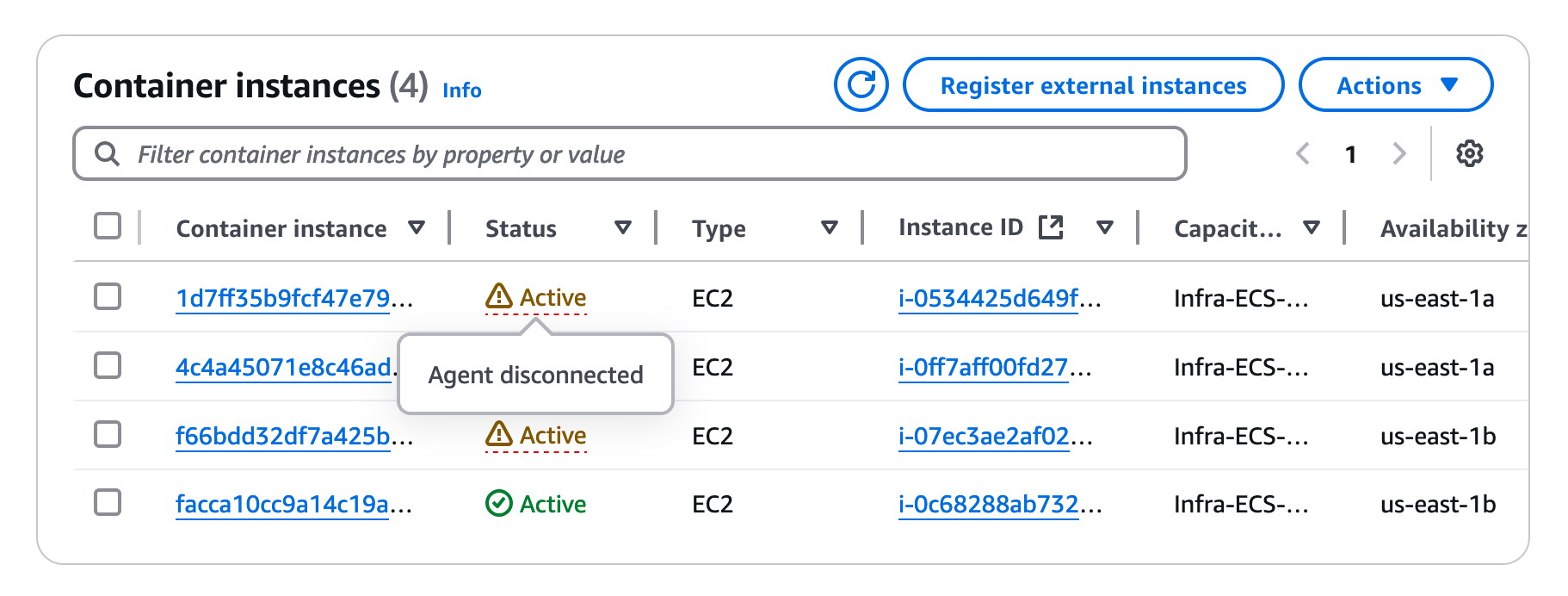
This happens because the ECS agent registers EC2 instances on their launch, but the warm pool instances stop after launch, and their ECS agent becomes unreachable. Though the ECS agent will be back online when an instance is started from the warm pool, and, honestly, I didn’t notice any real consequences of this warning, it’s still better to avoid it. We don’t want to push our luck, do we? Also, these warnings can be annoying, especially if your warm pool is quite large. Last but not least, such warnings may indicate problems with instances that are not in a warm pool. So, let’s keep our ECS cluster clean.
To avoid this warning, we should instruct the ECS agent to not register instances until they enter the InService state. This can be done by updating the ECS agent configuration file. To do so, we need to update the User Data of the EC2 Launch Template used by the Auto Scaling group. Depending on the used AMI, add the following lines to the User Data:
For Amazon Linux AMIs:
echo "ECS_WARM_POOLS_CHECK=true" >> /etc/ecs/ecs.configFor Bottlerocket AMIs:
[settings.autoscaling]
should-wait = trueAfter you update the User Data of the Launch Template, you need to refresh the instances in the Auto Scaling group. Open the Instance refresh tab on the Auto Scaling group page, click Start instance refresh, and follow the instructions. After the refresh is complete, check the ECS cluster page. Voila! No more warnings.
Gotcha #2: The trap of the “Reuse on scale in” option
You may have noticed the Reuse on scale in option when creating a warm pool. This option allows returning instances to the warm pool on scale in instead of terminating them. This may seem like a good idea: the fewer instances we terminate, the fewer instances we need to launch, and the better scalability is, right? This may be true in some cases, but with ECS, it’s a trap.

When ECS wants a capacity provider to scale in, it marks unneeded instances as Draining and waits for them to finish their tasks and terminate. The thing is that the Draining state is irreversible. If a draining instance is returned to the warm pool and then launched again, it will still be in the Draining state. ECS won’t be able to utilize that instance, while the Auto Scaling group will think it provided the requested capacity. Ultimately, this will lead to a situation when ECS can’t scale out at all.
Just remember: never enable the Reuse on scale in option for warm pools used with ECS.
Gotcha #3: AWS CloudFormation and UpdatePolicy
Another gotcha ambushes those who use CloudFormation to manage their infrastructure. This one is tricky, so let’s investigate it step by step.
First, let’s describe the situation. We have a created CloudFormation stack that contains an ECS cluster, an Auto Scaling group, and a warm pool. We want to update the stack to change the instance type of the Auto Scaling group. We update the template or its parameters and then update the stack. What happens next?
When updating an AWS::AutoScaling::AutoScalingGroup resource, CloudFormation acts according to one’s UpdatePolicy attribute. If we don’t specify the UpdatePolicy, CloudFormation will just update the Auto Scaling group’s Launch Template and won’t touch the instances. But we want the instances to be updated; that’s the whole point, right? So, we add the UpdatePolicy to the resource.
The first try: AutoScalingRollingUpdate
To perform a rolling update of the instances in an Auto Scaling group rather than wait for scaling activities to gradually replace older instances with newer instances, use the
AutoScalingRollingUpdatepolicy. This policy provides you the flexibility to specify whether CloudFormation replaces instances that are in an Auto Scaling group in batches or all at once without replacing the entire resource.
Looks exactly like what we need, right? So we add the UpdatePolicy to the AWS::AutoScaling::AutoScalingGroup resource:
EC2AutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
...
UpdatePolicy:
AutoScalingRollingUpdate:
MinInstancesInService: 1
MaxBatchSize: 1
PauseTime: PT15M
SuspendProcesses:
- HealthCheck
- ReplaceUnhealthy
- AZRebalance
- AlarmNotification
- ScheduledActions
WaitOnResourceSignals: true One of the interesting properties of the AutoScalingRollingUpdate policy is the WaitOnResourceSignals. When set to true, CloudFormation will wait for the instances to signal success before proceeding with the update. Let’s assume that we already configured our instances to signal success after they are launched.
We update the stack, and… the stack update is stuck in the UPDATE_IN_PROGRESS state. What’s wrong? Actually, we have two problems at once.
Problem #1: While the AutoScalingRollingUpdate policy description makes it look very smart, it’s pretty dumb in reality. It just increases the Auto Scaling group’s desired capacity, waits for the new instances to launch, and then decreases the desired capacity back. But what does an Auto Scale group with a warm pool do when it needs to scale out? It gets an instance from the warm pool. So, instead of getting a new instance with updated configuration, we’re getting an old instance from the warm pool.
Problem #2: An instance signals success only on the first boot. When an instance is fetched from a warm pool, it’s already booted, so it doesn’t signal success. CloudFormation waits for the signal that will never come, and the stack update is stuck.
Ideally, the AutoScalingRollingUpdate policy should utilize the Auto Scaling group’s Instance refresh feature. But it doesn’t. Why? I don’t know.

The second try: AutoScalingReplacingUpdate
To replace the Auto Scaling group and the instances it contains, use the
AutoScalingReplacingUpdatepolicy.
Ok, CloudFormation cannot perform a rolling update of the instances when a warm pool is involved. But it can replace the entire Auto Scaling group. Let’s try this approach:
EC2AutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
...
UpdatePolicy:
AutoScalingReplacingUpdate:
WillReplace: trueWe update the stack, CloudFormation creates a new Auto Scaling group, and… the stack update fails on updating the ECS cluster. What’s wrong this time?
The specified capacity provider is in use and cannot be removed
The problem is that some services in our ECS cluster are using the old Auto Scaling group as a capacity provider, so we can’t just replace it. If we were doing this manually, we would first associate the new Auto Scaling group with the ECS cluster, then update the services to use the new capacity provider, and only then remove the old Auto Scaling group. But CloudFormation can’t do this automatically.
A moment of despair
So, what are we left with?
- We can’t use the
AutoScalingRollingUpdatepolicy because it doesn’t know how to deal with warm pools. - We can’t use the
AutoScalingReplacingUpdatepolicy because it doesn’t know how to deal with ECS clusters. - We can disable the warm pool, update the Auto Scaling group using the
AutoScalingRollingUpdatepolicy, and then re-enable it. But it’s too much effort and too much risk. - We can run Instance refresh manually, but this is not what we want from CloudFormation.
But what if I tell you that we can make CloudFormation run the Instance refresh for us? Because we can!
The third try: A custom resource
There is one special type of CloudFormation resource that can do almost anything: AWS::CloudFormation::CustomResource (or Custom::<Something>). It can even order a pizza for you or send a message to your boss when you update the stack on Friday evening. But today, we will use it to run the Instance refresh for us.
Our custom resource will be backed by a Lambda function. Without further ado, here’s the template snippet:
# The IAM role for the Lambda function.
# It should have permission to start instance refreshes.
InstanceRefresherLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${AWS::StackName}-instance-refresher"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: "autoscaling-start-instance-refresh"
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- autoscaling:StartInstanceRefresh
Resource: "*"
# The Lambda function that will start the instance refresh on update or create.
# It will be triggered by the custom resource and requires the
# AutoScalingGroupName parameter.
InstanceRefresherLambda:
Type: AWS::Lambda::Function
Properties:
FunctionName: !Sub "${AWS::StackName}-instance-refresher"
Runtime: "python3.12"
Handler: "index.handler"
Role: !GetAtt "InstanceRefresherLambdaRole.Arn"
Timeout: 30
Code:
ZipFile: |
import cfnresponse
import json
import boto3
client = boto3.client('autoscaling')
def handler(event, context):
response_data = {}
try:
if event['RequestType'] != 'Create' and event['RequestType'] != 'Update':
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data, 'InstanceRefresher')
return
response = client.start_instance_refresh(
AutoScalingGroupName=event['ResourceProperties']['AutoScalingGroupName'],
Preferences={
'MinHealthyPercentage': 100,
'MaxHealthyPercentage': 200,
'SkipMatching': True,
'ScaleInProtectedInstances': 'Ignore',
'StandbyInstances': 'Ignore'
}
)
response_data['InstanceRefreshId'] = response['InstanceRefreshId']
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data, 'InstanceRefresher')
except Exception as e:
response_data['exception'] = e.__str__()
cfnresponse.send(event, context, cfnresponse.FAILED, response_data, 'InstanceRefresher') Now when we have the Lambda function, we can create the custom resource (EC2AutoScalingGroup is the Auto Scaling group resource in the template, and EC2LaunchTemplate is the Launch Template resource):
EC2InstanceRefresher:
Type: Custom::InstanceRefresher
Properties:
ServiceToken: !GetAtt "InstanceRefresherLambda.Arn"
ServiceTimeout: '60'
AutoScalingGroupName: !Ref "EC2AutoScalingGroup"
# The Lambda function doesn't actually need EC2LaunchTemplate.
# But we include it here to force the custom resource to run
# when the Launch Template is updated.
LaunchTemplate: !Ref "EC2LaunchTemplate"
LaunchTemplateVersion: !GetAtt "EC2LaunchTemplate.LatestVersionNumber"Now, when we update the stack, CloudFormation will run the Lambda function, which will start the Auto Scaling group’s Instance refresh process. Our custom resource won’t wait for the refresh to complete, but it will return success to CloudFormation. The stack update will continue, and the instances will be refreshed.
Note that we used the SkipMatching option of the start_instance_refresh API call. This option tells the Auto Scaling group to refresh only the instances that don’t match the Launch Template. So, the instances won’t be refreshed if you update only the Auto Scaling group but not the Launch Template.
While warm pools may be tricky when used with ECS, they are a pretty handy feature. Now that you know the gotchas, you can safely improve the scalability and availability of your ECS tasks. Happy scaling!
And the best part: if you want to use warm pools for your imgproxy installation, you don’t have to worry about the gotchas. We’ve already handled them in our CloudFormation template.